



Quick decision toggles
Use this quick triage before reading the full guide. Then validate with a 30-day pilot.
Choose Texta if...
- You want one workflow from visibility signal to assigned action.
- You run weekly operating reviews and need fast execution rhythm.
- You want source diagnostics, mention movement, and next-step guidance in the same workspace.
Choose peec.ai if...
- AI visibility analytics with benchmark-heavy reporting and BI-friendly measurement posture.
- Your team is willing to assemble decisions across multiple systems or longer analysis cycles.
- Your near-term priority is strategic reporting alignment more than operator execution speed.
Run a dual pilot if...
- Two or more departments disagree on reporting vs execution priorities.
- You need objective evidence before procurement or migration.
- You want a weighted scorecard built from your own prompts, competitors, and sources.
Texta vs peec.ai: Complete Decision Guide for AI Visibility Teams
Last updated: March 14, 2026
This page is a long-form, practitioner-level comparison designed for teams that need to select a primary AI visibility platform for the next 12-24 months. Instead of relying on a short feature checklist, this guide looks at the real operational question:
Which platform will help your team move faster from "we see what changed" to "we shipped the right fix and measured impact"?
The analysis below combines:
- Product and workflow analysis from the Texta application and product documentation.
- Public information from peec.ai docs and product pages.
- A rollout and governance model suitable for in-house teams and agencies.
- A weighted scorecard you can adapt to your context.
TL;DR Executive Summary
If your primary requirement is AI visibility monitoring with strong metric framing and ecosystem connectivity, peec.ai is a serious option, especially for teams that are already operating with a BI-first stack and want visibility data distributed into existing reporting pipelines.
If your primary requirement is end-to-end operating rhythm inside one product (prompt monitoring, mention movement, source analysis, and action suggestion loops in a single workflow), Texta is built for that execution model and typically reduces handoff friction between analysis and action.
Neither platform is "universally better." The better choice depends on:
- Whether you optimize for monitoring depth vs execution speed.
- Whether your team works through one product workflow vs multiple specialist tools.
- How much implementation overhead you can carry in the first 30-60 days.
- Who owns AI visibility inside your organization (SEO manager, content lead, brand team, RevOps analyst, agency pod, or cross-functional committee).
The practical recommendation:
- Choose Texta when your mandate is to run an ongoing action program and you want fewer translation steps between signal and execution.
- Choose peec.ai when your team prioritizes benchmark visibility analytics and downstream BI/reporting integrations with a strong internal analysis function.
- If your organization is large and divided by function, run a 30-day dual pilot with one shared scorecard before committing.
Scope, Method, and Fairness Notes
This comparison is intentionally explicit about method and limitations.
What is in scope
- Platform-level workflow fit for AI visibility operations.
- Metrics and interpretation model.
- Source and competitor diagnostics depth.
- Reporting and integration posture.
- Rollout complexity and governance impact.
- Team adoption profile by operating model.
What is out of scope
- Contractual commercial terms not publicly documented.
- Custom enterprise implementations that depend on private SOWs.
- Support quality as experienced by a specific account team (this varies by contract, region, and maturity).
Evidence and confidence model
Each claim falls into one of three confidence levels:
- High confidence: verified by product behavior or explicit platform documentation.
- Medium confidence: inferred from documented features plus observed UI patterns.
- Directional: strategic interpretation that still requires validation in your context.
You should treat this page as a decision accelerator, not a substitute for pilot testing.
Source references used in this guide
- peec.ai docs: Understanding your performance, Metrics overview, Understanding sources, API introduction, and related product docs.
- Texta product and marketing references from the current implementation and documentation in this repository.
At-a-Glance Comparison Table
| Dimension | Texta | peec.ai | Why this matters in practice |
|---|---|---|---|
| Core operating model | Monitoring + interpretation + action-oriented workflow | Monitoring + benchmarking + analytics interpretation workflow | Determines whether your team can execute in one workspace or must orchestrate across tools |
| Primary metrics | Prompt insights, mentions, source diagnostics, trends, action suggestions | Visibility, sentiment, position, source analysis, gap framing | Impacts what you can decide weekly without building custom transforms |
| Competitor context | Embedded in prompt and brand tracking workflows | Strong competitor benchmarking in visibility and ranking context | Critical for narrative quality in stakeholder reviews |
| Source intelligence | Consolidated source impact views with decision framing | Domain and URL analysis with gap analysis and source classification | Influences your content and partnership backlog quality |
| Action guidance | Product-level next-step suggestions integrated in workflow | Action inspiration and interpretation guidance in docs/workflow | Decides whether strategy output is native vs analyst-assembled |
| Integration posture | Product workflow first; can be integrated into broader stack | Strong documented API/connector posture (including BI patterns) | Changes ownership model between product ops and analytics ops |
| Rollout style | Guided setup suited to execution cadence | Structured setup with strong emphasis on metric interpretation | Impacts time-to-first-useful-review and onboarding burden |
| Best fit (typical) | Teams optimizing for action velocity and operational continuity | Teams optimizing for analytics benchmarking and external reporting | Align platform with your team DNA, not generic feature count |
Visual Walkthrough: Real Screens and Product Surfaces
Texta screens
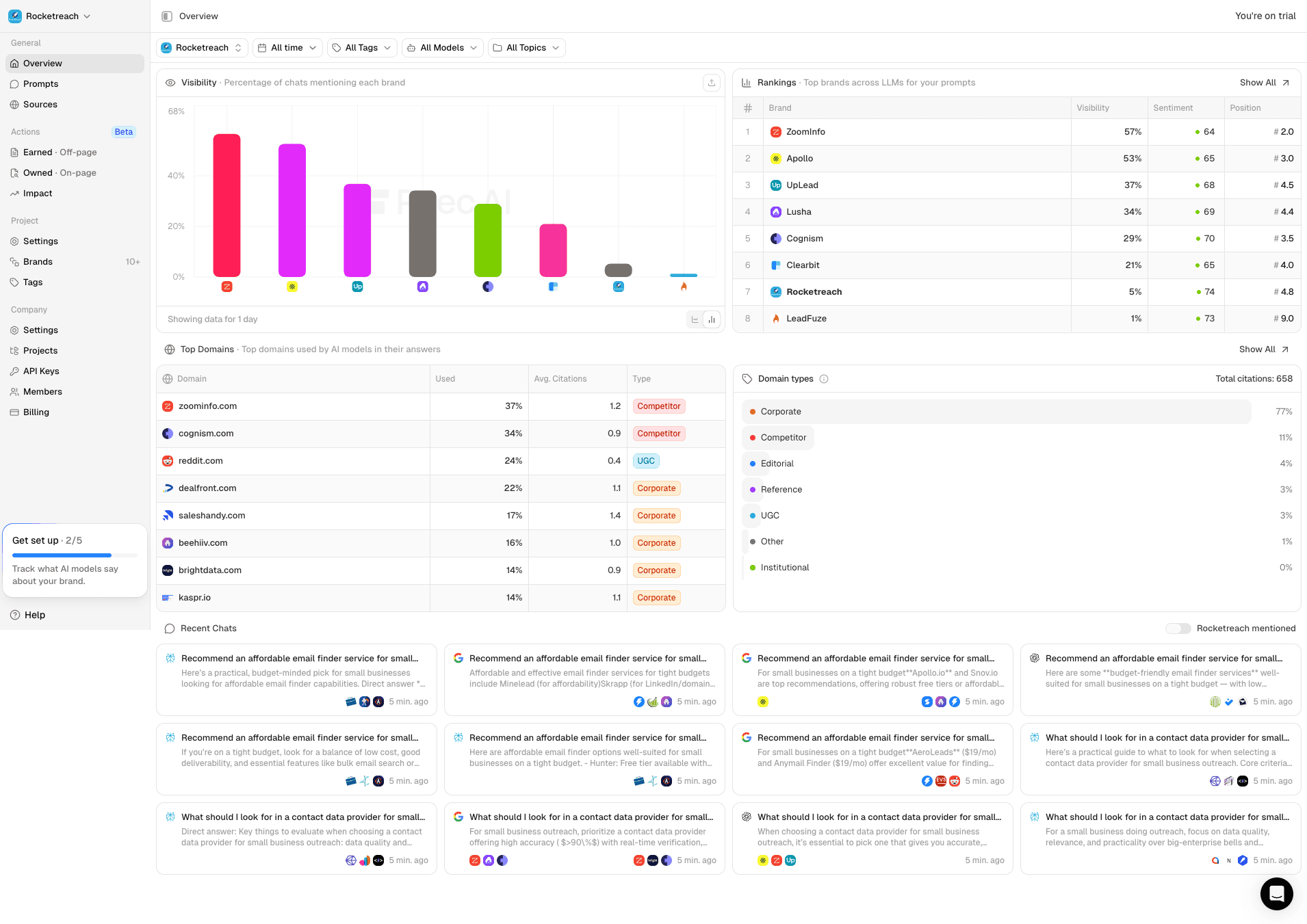
Texta overview surface focused on multi-signal monitoring and operating rhythm.
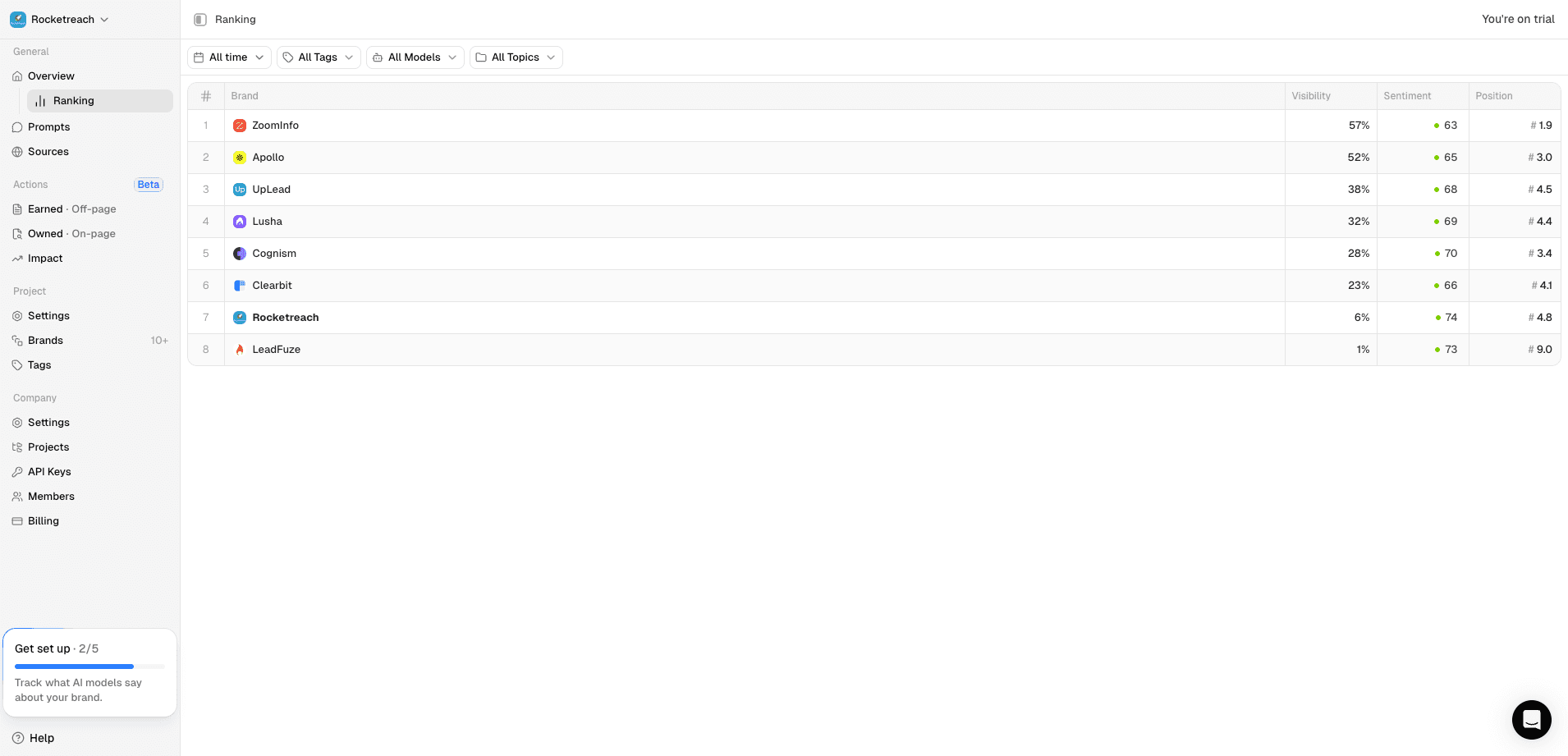
Texta ranking and performance context for competitive visibility reviews.
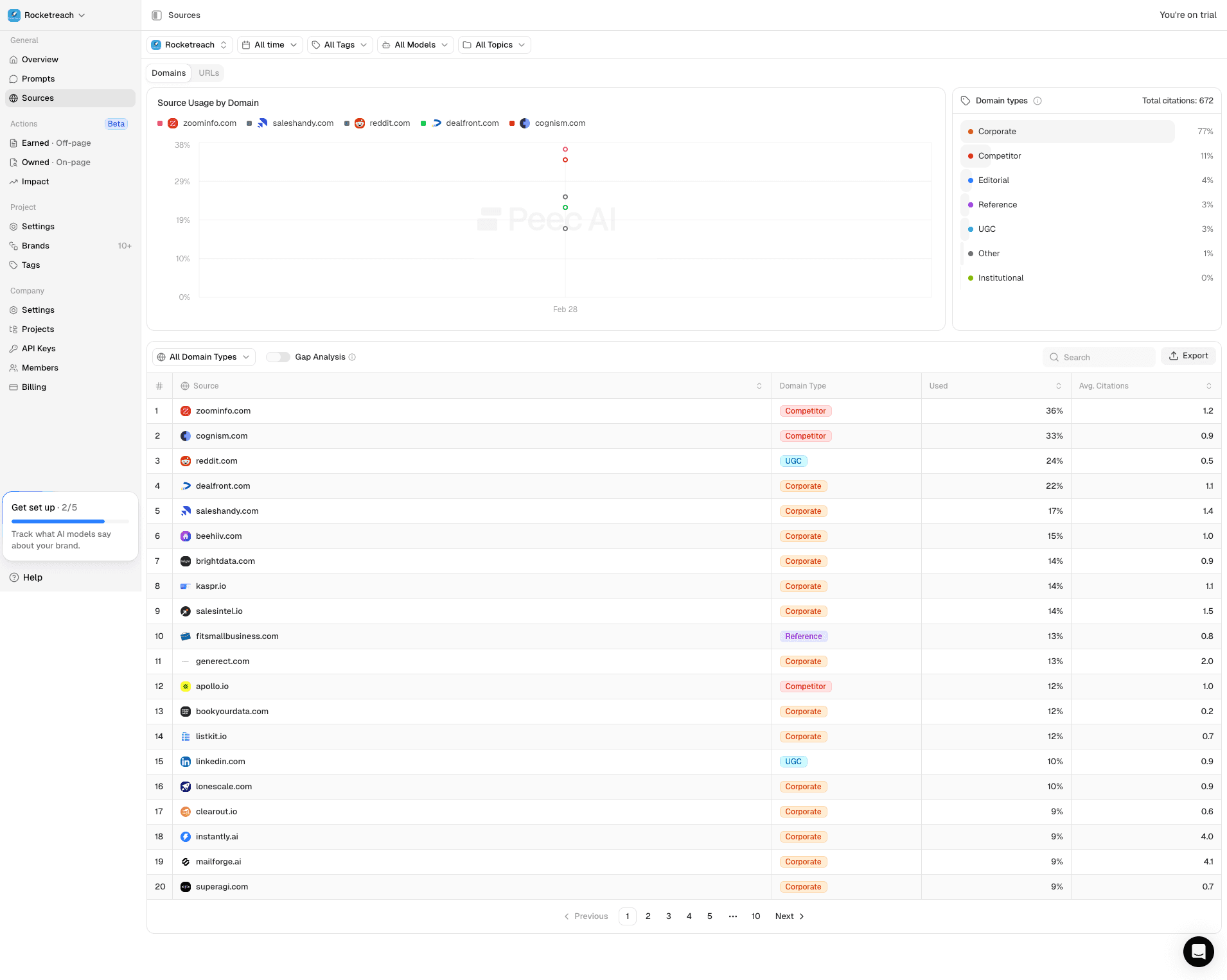
Texta source-domain diagnostics used for source-level prioritization.
peec.ai screens

peec.ai positioning and category framing from public site.

Public documentation view on visibility and performance interpretation.

Public documentation view on source and gap analysis concepts.
Graph 1: Capability Scorecard by Weighted Axis

This chart models one realistic enterprise scenario where weights are distributed across actionability, source diagnostics, workflow continuity, integrations, reporting, and onboarding speed. The key takeaway is not "a universal winner." The key takeaway is that the relative advantage shifts based on where you place weight:
- Heavier weight on integrations and BI distribution improves peec.ai's relative position.
- Heavier weight on in-product action loops and rollout velocity improves Texta's relative position.
If your steering committee cannot agree on weights, do not choose a vendor yet. Agree on weighting first.
Deep Dive 1: Measurement Model and Decision Quality
Most platform evaluations fail because teams compare labels, not decision outcomes. Both products can show numbers. The real issue is whether your operators can answer four recurring weekly questions with confidence:
- What changed materially?
- Why did it change?
- What should we do in priority order?
- Did the action improve the right KPI?
peec.ai's public metric framing is clear around visibility, sentiment, and position, with direct competitor context and strong explanation surfaces in docs. This is useful for analytical consistency and stakeholder communication, especially when your team already understands metric semantics and can bridge from score movement to tactical workstreams.
Texta's product proposition emphasizes the same monitoring core but places more product focus on the "what next" layer inside the same operating workflow. That can reduce interpretation debt when teams are understaffed on analytics translation and need the platform to produce decision pressure without waiting for a separate analysis cycle.
In large teams, this distinction becomes structural:
- Analytics-led org: often prefers explicit benchmark layers and high-control interpretation patterns.
- Execution-led org: often prefers in-product recommendation loops and lower handoff overhead.
If your org has both patterns, use a dual-track model:
- Track visibility and rank deltas in one shared weekly scorecard.
- Run tactical backlog execution from a single accountable workflow.
- Require each action to include expected metric impact, affected prompts, and source-level rationale.
Practical scoring template for this dimension
| Criterion | Texta tendency | peec.ai tendency | What to test in pilot |
|---|---|---|---|
| Metric interpretability for non-analysts | Higher | Medium-high | Can content and brand leads explain movement without analyst mediation? |
| Competitive benchmark depth | High | High | Can team identify rank context shifts quickly? |
| Transition from signal to action | High | Medium | Time from "trend observed" to "task assigned" |
| Leadership narrative readiness | High | High | Can CMO consume weekly report without deck rewrite? |
Deep Dive 2: Prompt Strategy, Taxonomy, and Measurement Integrity
Prompt architecture determines whether your AI visibility program produces strategic clarity or noise. Both platforms support prompt-driven analysis, but the organizational discipline around prompts usually matters more than vendor selection.
A robust prompt strategy has three layers:
- Intent layer: informational, comparative, transactional, and trust-building intents.
- Business layer: mapped to product lines, geographies, customer segments, funnel stages.
- Change layer: prompts likely to move because of launches, seasonality, policy shifts, or competitor campaigns.
Where teams struggle is not "creating prompts." They struggle with prompt governance:
- Duplicate prompts with slightly different wording.
- Missing ownership per prompt cluster.
- Inconsistent tagging over time.
- No retirement policy for stale prompts.
Texta's operating model aligns well with a governance setup where prompt clusters are continuously tied to action outputs and source checks. peec.ai documentation also emphasizes setup quality and competitor-aware prompt systems, which supports benchmark rigor when your analysts enforce taxonomy discipline.
Prompt governance checklist (independent of vendor)
| Governance rule | Why it matters |
|---|---|
| One owner per prompt cluster | Avoids orphaned prompts and untriaged changes |
| Mandatory topic and lifecycle tags | Enables reliable cohort analysis |
| Monthly prompt audit | Removes stale and low-signal prompts |
| Prompt quality acceptance criteria | Ensures wording reflects real user intent |
| Change log for prompt edits | Preserves trend comparability over time |
Common failure pattern to avoid
Teams often scale from 30 to 300 prompts too quickly, then discover that reporting confidence decreases. Growth in prompt count without governance usually lowers decision quality. During pilot, target fewer prompts, stronger governance. Expand only after your weekly review cadence is stable for at least four cycles.
Deep Dive 3: Source Intelligence and Gap Identification
Source analysis is where AI visibility programs move from descriptive dashboards to concrete execution plans. Both products expose source-level perspectives, but teams should evaluate source tooling through one practical question:
Can we turn source diagnostics into prioritized, owner-assigned work within one review cycle?
peec.ai's documented source model includes domain and URL analysis with explicit gap framing and source typing. This helps teams identify where competitors appear and where the brand is absent. For analytics-heavy organizations, that is a strong base for structured source opportunity maps.
Texta's source framing is designed to fit into an integrated operating workflow where source impact is interpreted alongside prompts, mentions, and trends. In practice, this can reduce fragmentation when teams do not want source opportunities living in separate analysis artifacts.
Source operations maturity model
| Maturity stage | Typical behavior | Platform implications |
|---|---|---|
| Stage 1: Snapshot monitoring | Teams inspect source lists occasionally | Either platform works; risk is no execution loop |
| Stage 2: Structured triage | Teams classify opportunities weekly | Strong source segmentation and filtering become mandatory |
| Stage 3: Execution pipeline | Teams map source opportunities to content/outreach backlog | Tight integration with action workflow becomes high leverage |
| Stage 4: Impact accountability | Teams measure outcome per source intervention | Need robust experiment logging and post-action reporting |
Recommended pilot tests for source workflows
- Select 15 high-frequency source domains with competitor mention concentration.
- Map each domain to one intervention hypothesis.
- Assign an owner and due date.
- Re-measure after two cycles.
- Evaluate how many interventions reached completion and produced measurable movement.
Do not judge source tooling by visual quality alone. Judge by completed interventions per cycle.
Deep Dive 4: Competitor Benchmarking and Strategic Positioning
Competitor tracking quality determines whether your team interprets movement as market noise or strategic signal. Both Texta and peec.ai support competitor-aware analysis, but their value emerges differently depending on how your organization runs market intelligence.
For benchmark-centric teams, peec.ai's documented model around brand visibility, position interpretation, and competitor context can be a strong foundation, particularly when combined with BI workflows and custom reporting logic.
For teams that want competitor insight tightly coupled with action queues and source diagnostics in one workspace, Texta's operating narrative aligns better with a workflow-led model.
Competitor intelligence questions your platform must answer weekly
| Question | Why it matters |
|---|---|
| Which competitor gained visibility in high-intent prompts this week? | Prioritizes immediate defensive actions |
| Did our rank improve only where sentiment dropped? | Prevents false-positive "wins" |
| Which source domains are amplifying competitor growth? | Focuses outreach and content interventions |
| Are we losing across one topic cluster or across all clusters? | Distinguishes tactical issue from strategic drift |
| Which competitor wins are stable vs volatile? | Helps sequence short-term vs long-term responses |
Tactical recommendation
Use a two-layer competitor review:
- Layer A: Weekly movement review for operational actions.
- Layer B: Monthly structural review for positioning and narrative shifts.
If you collapse these layers into one meeting, teams either overreact to noise or ignore structural drift.
Deep Dive 5: Actionability and Cross-Functional Execution
The central operational tradeoff in this comparison is actionability architecture.
A monitoring-first workflow is excellent for analytical rigor, but many organizations stall if translation into tasks depends on one or two specialists. An action-oriented workflow can accelerate execution, but only if recommendation quality is transparent and tied to measurable outcomes.
Texta's product direction emphasizes this action loop as a native part of the platform. peec.ai's ecosystem provides robust insight frameworks and "actions" framing in docs and workflows, which can be powerful when teams have a mature process for converting insights into roadmap items.
What to measure in your pilot
| KPI | Target range for a healthy rollout |
|---|---|
| Time from signal detection to task creation | < 48 hours |
| Time from task creation to first implementation | < 10 business days |
| Share of actions with explicit metric hypothesis | > 80% |
| Share of actions with post-change measurement | > 70% |
| Weekly review completion rate | > 90% of planned cadences |
Execution anti-patterns
- Building dashboards without owner-level action routing.
- Logging actions without measurable hypotheses.
- Running one-time fixes without replaying prompts after implementation.
- Treating competitor movement as commentary instead of backlog input.
If your selected platform cannot enforce these disciplines through workflow design, you will need additional process instrumentation.
Deep Dive 6: Reporting, Integrations, and Governance Fit
Integration posture is one of the clearest differentiators in real enterprise environments.
If your organization already has a mature data team and standardized BI practices, peec.ai's public API and connector-oriented documentation may align naturally with your operating stack. This can be a major advantage when AI visibility data must flow into board-level or RevOps-level reporting frameworks.
If your organization is still building AI visibility governance and needs a product-native operating rhythm before expanding into complex reporting pipelines, Texta's integrated workflow approach can reduce implementation overhead and simplify accountability.
Integration fit matrix
| Org profile | Recommended default | Reason |
|---|---|---|
| Strong analytics engineering + BI governance | peec.ai-leaning | High leverage from API/connector posture and custom modeling |
| Lean marketing ops team, limited data engineering | Texta-leaning | Faster adoption with fewer dependency chains |
| Agency with mixed client maturity | Hybrid pilot | May need monitoring rigor + action velocity depending on account tier |
| Multi-brand enterprise with central PMO | Dual-track evaluation | Often requires both standardized benchmarking and action operating loop |
Governance gates before full rollout
- Named executive sponsor.
- Weekly operating cadence owner.
- Prompt taxonomy owner.
- Source intervention owner.
- Reporting and data quality owner.
- Experimentation and attribution owner.
A platform cannot replace governance. It can only make governance easier or harder to execute.
Graph 2: Rollout Effort Curve (30 Days)

This model is intentionally conservative. It assumes a cross-functional team with marketing, SEO/content, and analytics representation. The curve difference does not mean one platform is "easy" and the other is "hard." It reflects different implementation priorities:
- Action-driven configuration tends to spend earlier effort on workflow setup and team rituals.
- Benchmark-driven configuration tends to spend earlier effort on metric interpretation and data distribution.
In both cases, rollout success depends more on operating cadence discipline than UI onboarding completion.
Deep Dive 7: Time-to-Value by Team Type
The same platform can perform differently depending on team shape. This section maps typical team archetypes to expected time-to-value patterns.
Archetype A: In-house growth team (8-20 people)
- Usually wants weekly execution loops and fast backlog activation.
- Often lacks dedicated analytics engineering for the first phase.
- Benefits from tighter in-product interpretation-to-action pathway.
Archetype B: Enterprise marketing analytics pod
- Has BI and data governance standards.
- Needs confidence in metric lineage and cross-system reporting.
- Accepts higher setup complexity if long-term reporting control improves.
Archetype C: Agency client pod
- Needs repeatable framework across heterogeneous clients.
- Must explain strategy quickly to non-technical stakeholders.
- Requires structured scorecards and playbooks more than custom analytics logic.
Time-to-first-credible-review benchmark
| Team archetype | Texta expected range | peec.ai expected range | Notes |
|---|---|---|---|
| In-house growth team | 7-14 days | 10-21 days | Depends on prompt governance readiness |
| Enterprise analytics pod | 14-28 days | 14-28 days | Integration and data policy dominate timeline |
| Agency pod | 10-21 days | 10-24 days | Process standardization is critical |
These are directional ranges, not vendor guarantees.
Deep Dive 8: Cost Model and Hidden Operational Load
Pricing comparison pages usually fail because they compare list price only. In AI visibility programs, hidden cost drivers often dominate by month three:
- Analyst time for weekly interpretation.
- Content and SEO implementation capacity.
- Data operations overhead (if external reporting stack is required).
- Meeting overhead and decision latency.
To avoid a false economy, compute total operating cost, not only subscription cost.
Total cost model template
| Cost bucket | Formula | Typical driver |
|---|---|---|
| Platform subscription | Vendor price x plan | Seat/volume and contract terms |
| Program management | Weekly hours x blended rate | Cadence ownership complexity |
| Analytics interpretation | Analyst hours x rate | Need for custom score synthesis |
| Content execution | Writer/editor/SEO hours x rate | Number of interventions per cycle |
| Stakeholder reporting | Reporting hours x rate | Board and leadership expectations |
Example scenario (illustrative only)
| Scenario | Lower-bound monthly cost | Mid monthly cost | Upper-bound monthly cost |
|---|---|---|---|
| Lean team (single brand, 60 prompts) | $4,500 | $7,200 | $10,800 |
| Growth team (multi-topic, 150 prompts) | $9,500 | $14,700 | $22,000 |
| Enterprise pod (multi-market, 300+ prompts) | $18,000 | $29,000 | $44,000 |
The platform subscription is usually the smallest line item by month two. Optimization should focus on reducing interpretation and execution waste.
Graph 3: Use-Case Fit Matrix

The fit matrix intentionally highlights that both platforms are strong in core monitoring scenarios. Differentiation tends to appear in:
- How quickly a team can move from diagnosis to implementation.
- How much custom reporting and integration control is required.
- Whether the organization values platform-native action loops or externalized analytics orchestration.
Deep Dive 9: Risk Register and Mitigation Plan
No platform decision is complete without a risk view. Use this register before procurement:
| Risk | Typical trigger | Impact | Mitigation |
|---|---|---|---|
| Metric misinterpretation | Teams mix visibility with sentiment signals | Wrong priorities | Define metric glossary and decision rules in week 1 |
| Prompt set drift | Ad hoc prompt additions | Trend inconsistency | Monthly prompt governance and change log |
| Source intervention backlog bloat | Too many opportunities, unclear owners | Low completion rates | Cap weekly interventions and require owner assignment |
| Executive overreaction to short-term noise | Daily fluctuations interpreted as trend | Churn in strategy | Use rolling windows and significance thresholds |
| Tool underutilization | Setup done, cadence not enforced | Wasted spend | Tie usage to weekly operating ritual and KPI scorecard |
| Integration overengineering | Premature BI integration scope | Slow time-to-value | Phase integrations after first stable 4-week cycle |
Governance compact (recommended)
Before full rollout, formalize:
- Weekly review owner.
- Monthly strategy owner.
- Prompt governance owner.
- Source intervention owner.
- Reporting owner.
- Escalation path for major visibility drops.
This compact is often more predictive of ROI than platform feature breadth.
30/60/90 Pilot Blueprint (Use This Before Final Selection)
The best way to choose between Texta and peec.ai is a controlled pilot with shared prompts, shared competitors, and shared success criteria.
Day 0-10: Baseline and setup
- Build a 50-80 prompt baseline by intent cluster.
- Add 5-8 direct competitors.
- Define mandatory tags and ownership.
- Establish baseline visibility/sentiment/position reporting.
- Create source opportunity board structure.
Day 11-30: Weekly operating loop
- Run weekly review with fixed agenda:
- Prompt movement highlights.
- Competitor movement highlights.
- Source opportunity review.
- Action assignment and due dates.
- Require hypothesis for every action.
- Re-measure key prompts after each completed action.
Day 31-60: Scale and governance stress-test
- Expand prompt inventory by 20-30%.
- Add one new stakeholder group (brand, PR, or product marketing).
- Test executive reporting quality.
- Track completion rate and cycle time.
Day 61-90: Decision and rollout design
- Compare final weighted scorecard.
- Compare operational KPI outcomes.
- Select primary platform.
- Define migration or coexistence path.
Pilot scorecard template
| Category | Weight | Texta score (1-10) | peec.ai score (1-10) | Notes |
|---|---|---|---|---|
| Signal clarity | 15 | |||
| Actionability | 20 | |||
| Source diagnostics | 15 | |||
| Competitor context | 10 | |||
| Reporting quality | 10 | |||
| Integration readiness | 10 | |||
| Team adoption | 10 | |||
| Governance fit | 10 | |||
| Total weighted | 100 |
Use this exact table in both pilots to prevent evaluation drift.
Scenario-Based Recommendations
Scenario 1: You need immediate execution acceleration
Choose Texta-first if your near-term objective is to establish a weekly operating system that converts visibility signals into concrete actions with low translation overhead.
Why:
- Strong alignment to action-oriented workflow narrative.
- Clear fit for teams with limited analytics bandwidth.
- Easier adoption path for cross-functional operators who are not BI specialists.
Scenario 2: You need analytics standardization and BI extensibility
Choose peec.ai-first if your organization has strong analytics maturity and prioritizes benchmark interpretation, data extraction, and standardized external reporting pipelines.
Why:
- Clear public API and reporting ecosystem posture.
- Strong metric framing and competitor benchmark structure.
- Good fit for teams with dedicated analytics ownership.
Scenario 3: You are an agency serving mixed client profiles
Run dual-mode pilot and choose by client segment:
- Execution-heavy clients: Texta-leaning.
- Analytics-heavy clients: peec.ai-leaning.
If tooling sprawl is a concern, prioritize the platform that best fits your largest revenue segment, then create a migration/exception policy for outlier clients.
Scenario 4: You are a multi-brand enterprise with strict governance
Start with a governance pilot before scaling seats:
- Validate prompt taxonomy durability.
- Validate executive reporting reliability.
- Validate intervention completion rates.
Select the platform that achieves the highest completed-action-to-signal ratio, not the highest number of dashboard modules.
FAQ for Procurement and Operators
1) Which platform has the stronger "single pane" workflow?
Texta generally presents a tighter action loop in one workspace narrative. peec.ai provides strong visibility analytics and can be equally effective when your organization is comfortable orchestrating execution through adjacent systems.
2) Which platform is better for competitor benchmarking?
Both are strong in competitor-aware analysis. peec.ai documentation emphasizes benchmark interpretation depth; Texta emphasizes benchmark context inside a broader action workflow.
3) Which one is easier for non-technical stakeholders?
Teams with lower analytics bandwidth often adopt faster when interpretation and next actions are tightly integrated in product workflows. Teams with strong analytics support can be successful on either platform.
4) Should we choose based on pricing page alone?
No. Subscription price is usually not the largest cost component in month two onward. Use total operating cost and completion metrics.
5) How long should a fair pilot run?
Minimum 30 days for directional signal. 60-90 days is ideal for governance and adoption validation.
6) Can we run both in parallel for a time?
Yes, if you define one shared scorecard and avoid unbounded process duplication.
7) What is the biggest selection mistake?
Choosing by feature list without validating operating cadence outcomes.
8) What KPI should decide the winner?
A balanced set:
- Signal-to-action cycle time.
- Action completion rate.
- Measured post-action visibility movement.
- Executive reporting trust score.
9) What if both score similarly?
Choose the one that better matches your team operating style and has lower organizational friction.
10) How do we avoid lock-in risk?
Keep prompt taxonomy, scorecard logic, and intervention logs platform-agnostic from day one.
Final Recommendation Framework
If you need one concise decision framework, use this:
- Define your operating archetype.
- Set weights before demos.
- Run a shared 30/60/90 pilot.
- Score outcomes, not impressions.
- Select platform by execution evidence.
In most organizations, platform success is less about "which dashboard has more features" and more about this equation:
(Signal clarity × Action velocity × Governance discipline) / Coordination overhead
Choose the platform that improves this equation in your real weekly operating environment.
Appendix A: Expanded Head-to-Head Capability Notes
Visibility and ranking interpretation
Both platforms support visibility-oriented analysis with competitor context. peec.ai's public docs explain visibility, sentiment, and position semantics clearly, which is valuable when onboarding analysts and stakeholders. Texta's workflow emphasizes moving from these indicators to concrete interventions in a unified operating experience.
Source diagnostics and gap analysis
peec.ai documentation presents strong source and gap interpretation surfaces, including domain and URL perspectives. Texta provides source impact views integrated with broader monitoring and action context. The operational choice depends on whether your team prefers source analysis as an analytic specialty lane or as part of a unified execution lane.
Team operating design
Texta is typically favored by teams that want analysis and action tightly coupled. peec.ai is often favored by teams that want metric clarity with externalized reporting and custom analytics control.
Reporting governance
If your leadership cadence requires standardized BI artifacts, assess integration and export pathways early in pilot. If your priority is in-team execution and measurable weekly progress, focus on action completion and time-to-implementation metrics.
Data quality controls
No platform can solve weak prompt governance. Your first month should prioritize prompt hygiene, competitor alias controls, and review cadence consistency.
Appendix B: Ready-to-Use Weekly Review Agenda
Duration: 45 minutes
Participants: marketing lead, SEO/content lead, analytics owner, execution owner
- 5 min – KPI pulse
- Visibility movement summary.
- Major competitor movement.
- 10 min – Prompt cluster diagnostics
- Top gainers/decliners.
- Confidence check on anomalies.
- 10 min – Source opportunity review
- High-priority domains/URLs.
- Intervention proposals.
- 15 min – Action routing
- Owner, due date, expected metric impact.
- 5 min – Risk and escalation
- Blockers, dependencies, leadership escalations.
Meeting output standard
Every meeting should produce:
- 3-7 prioritized actions.
- One clear executive summary.
- One risk note with owner.
- One experiment note for next review.
Without standardized output, platform value becomes anecdotal and difficult to defend.
Appendix C: Decision Confidence Checklist
Mark each as Yes/No before procurement:
- We validated with live prompts, not demo prompts.
- We tested at least one high-variance week.
- We measured action completion, not just dashboard satisfaction.
- We validated reporting outputs with real executive stakeholders.
- We documented rollout roles and ownership.
- We estimated total operating cost, not only license cost.
- We tested source interventions and measured post-action movement.
- We ran one retrospective on pilot process quality.
If you have fewer than six "Yes" answers, extend the pilot before final commitment.
Closing Note
Texta and peec.ai both represent serious approaches to AI visibility intelligence. The right decision is not a branding exercise; it is an operating model decision.
Use this guide to reduce ambiguity, run a rigorous pilot, and choose based on evidence from your own workflow. That decision quality will matter more than any single feature comparison line item.
Appendix D: Migration Playbook (When You Replace an Existing Stack)
Many teams reading comparison pages are not buying a platform from scratch. They are replacing an incumbent setup made of spreadsheets, BI dashboards, point tools, and manual review rituals. Migration success depends less on "import" mechanics and more on operating continuity.
Phase 1: Discovery and baseline lock
Before any migration work starts, freeze a baseline for 2-4 weeks:
- Current prompt inventory and ownership.
- Current competitor list and alias rules.
- Current source intervention backlog.
- Current reporting cadence and audience map.
Do not start migration without this baseline, because teams otherwise lose comparability and cannot prove performance continuity.
Phase 2: Taxonomy normalization
Most migrations fail here. Prompt tags, topic labels, and owner fields are usually inconsistent across legacy systems. Build a normalized taxonomy before data transfer:
- One canonical prompt naming convention.
- One topic hierarchy.
- One owner model (primary, backup, approver).
- One status model for interventions (proposed, planned, in progress, validated, archived).
This step reduces long-term reporting ambiguity and prevents "same metric, different meaning" errors.
Phase 3: Parallel run window
Run old and new systems in parallel for a limited period (usually 2-6 weeks) with strict scope:
- Same prompt cohort.
- Same competitor cohort.
- Same weekly review format.
- Same KPI definitions.
The goal is not to reach identical values in every line item. The goal is to verify that directional movement, decision confidence, and action routing quality are at least as strong in the new platform.
Phase 4: Cutover and stabilization
Once parallel-run acceptance criteria are met, execute cutover:
- Freeze legacy edits.
- Move weekly review to primary platform.
- Keep legacy read-only for historical reference.
- Run two post-cutover retrospectives (week 2 and week 6).
Do not keep both systems "equally active" beyond stabilization unless there is a clear governance reason. Long-term dual operations create coordination drag and reporting conflicts.
Migration acceptance criteria template
| Acceptance criterion | Target | Pass/Fail |
|---|---|---|
| Prompt coverage continuity | >= 95% of baseline prompt set active in new system | |
| Competitor coverage continuity | >= 95% of baseline competitor set active | |
| Weekly review completion | >= 90% during migration window | |
| Action routing continuity | >= 80% of actions assigned with owner + due date | |
| Post-action measurement continuity | >= 70% actions re-measured in next cycle | |
| Executive reporting readiness | Weekly pack accepted without major rework |
Migration communication plan
Use a three-audience communication pattern:
- Operators: tactical guidance and day-to-day process changes.
- Leadership: risk, timeline, and decision confidence updates.
- Adjacent teams (PR, product marketing, RevOps): what changes in data interpretation and expectations.
If communications are generic, teams often misread temporary volatility as platform failure.
Common migration mistakes
- Treating migration as a tooling project instead of an operating model update.
- Moving prompts without moving ownership.
- Preserving old dashboards with old definitions while presenting new definitions in reviews.
- Skipping the parallel-run window because "we already trust the vendor."
Recommended roles and RACI sketch
| Role | Responsibility |
|---|---|
| Program lead | Own migration timeline, risk log, decision gates |
| Taxonomy owner | Approve tags, topics, naming conventions |
| Analytics owner | Validate KPI continuity and executive reporting |
| Execution owner | Ensure interventions are routed and completed |
| Platform admin | Configure access, permissions, and environment settings |
| Executive sponsor | Resolve cross-functional blockers and approve cutover |
Post-migration optimization
After successful cutover, schedule a 45-day optimization sprint:
- Remove low-signal prompts.
- Tune competitor cohorts by strategic relevance.
- Improve intervention templates for repeated action types.
- Simplify executive reporting to 3-5 decision metrics.
- Document "what changed and why" examples for onboarding new stakeholders.
This sprint is where most teams recover 20-40% operational efficiency after the disruption of migration.
Final migration guidance
Pick the migration path that protects weekly operating rhythm. A technically elegant migration that interrupts your review cadence for a month is usually a net loss. A pragmatic migration with clear governance, stable score definitions, and strong role clarity almost always wins.
Related comparisons
Use these internal comparison pages to evaluate adjacent options and keep your research workflow in one place.
| Page | Focus | Link |
|---|---|---|
| Texta vs Profound | Detailed comparison for organizations balancing operator speed against enterprise reporting and governance requirements. | Open page |
| Texta vs Promptwatch | Practical guide for teams weighing market-facing AI visibility operations against prompt observability priorities. | Open page |
| Texta vs Semrush | Useful for teams balancing classic SEO stack depth against AI-answer visibility execution and action loops. | Open page |
| Texta vs Ahrefs | Decision guide for organizations running both SEO and GEO priorities with limited team bandwidth. | Open page |
| Texta vs AirOps | Clear breakdown for teams choosing between optimization insights and production automation as their first AI investment. | Open page |
| Texta vs AthenaHQ | Built for teams evaluating two AI visibility-focused tools with different execution and reporting priorities. | Open page |
| Texta vs Otterly.ai | Useful for teams deciding whether to start with lightweight tracking or a deeper execution-focused GEO workflow. | Open page |
| Texta vs rankshift.ai | Decision framework for teams that need both ranking clarity and faster execution from visibility signals. | Open page |